When I started this blog, I wanted to use the Ghost blogging platform. I was looking for a free solution for hosting it, and I didn’t mind a little tinkering in order to get it running.
At the time, the best approach I could find was hosting it on an Amazon EC2 instance, since Amazon offered a Free Tier, with which you could run a small Linux instance for free, for the duration of one year.
The one year duration of the Amazon Free Tier is coming to an end, so a couple of weeks ago I started to look for an alternative to host my blog. I found the OpenShift platform by Red Hat, where you can run a small machine instance for free, which seemed like the perfect alternative to run my blog.
The only problem was that on Amazon I was using the file-based SQLite approach to store my blog data, whereas on OpenShift the recommended method either MySql or Postgre. I decided to go with Postgre, so I needed to migrate all my blog data there from SQLite.
Getting started
Creating a new Ghost blog on OpenShift is very simple, you can follow the guide on howtoinstallghost.
After you created the new blog, you need to clone its git repository, copy all your static content, namely the content/apps and content/themes directories overwriting the existing content, and push it to the remote.
The other, much bigger task is to migrate the actual data from SQLite to the Postgre database.
Connecting to the Postgre DB running on OpenShift
Connecting to your new Postgre DB is simple, but it needs an extra step. Because of security reasons, you need a client side tool, which will open a secure tunnel between your computer and the DB server.
First you have to install rhc by following the official guide.
After this, you have to initiate port-forwarding by executing the following command:
rhc port-forward -a your-app-name
In the output of the command you’ll find the port on localhost to which you have to connect to reach your Postgre DB.
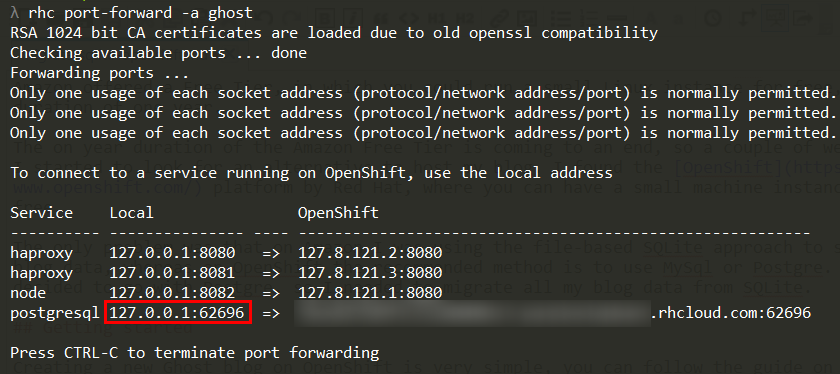
So I needed to connect to localhost:62696.
For actually connecting to the DB, I was using the official pgAdmin client, but probably you can do the same thing with the command-line Postgre client too.
Clearing the DB
We want to migrate all our data and settings from the existing DB, however, the OpenShift Postgre DB contains some sample data by default. That data needs to be erased.
With PostgreSQL, you can erase all data from a table using the TRUNCATE TABLE command. Furthermore, you can find a helpful little procedure in this SO answer, with which you can truncate all your tables in one step. (But if you just manually clear all your tables, that works too.)
Migrate Sqlite data
With Sqlite3 it’s easy to create a SQL script that creates an exact copy of our database and fills all the existing data into it. We can do this with the following command:
sqlite3 ghost.db .dump | grep -v "^CREATE" | grep -v "PRAGMA" | grep -v "sqlite_sequence" > blog.dump.sql
With piping a couple of greps together we remove all the lines we don’t want to use with Postgre. (I’ve found this command on Leonardo Andrade’s blog.]
In order to be able to run this script on my Postgre DB, I needed to do a couple of tweaks on the script. Luckily the whole script is enclosed in one transaction, so you’re free to try to run it again and again, it’ll only insert anything into your DB after you successfully fixed all problems in the script.
If you end up in a situation where you accidentally inserted something into your DB anyway, simply purge all records again and start over.
Fix errors in the Sqlite dump script
There are a couple of incompatibilities between Sqlite and Postgre that we have to address if we want to successfully execute this script against our Postgre DB.
I used a couple of very simple regexp replacements to fix all the different errors I encountered. You can use any text editor that supports regexp replacements, such as Sublime Text.
Fix boolean literals
Sqlite does not have a separate boolean data type, rather the booleans are represented with integers having either 0 or 1 as their value. In the Postgre schema, the same columns are represented with booleans, and the literals 0 and 1 are not acceptable as boolean values, so our script will report an error everywhere booleans are used. The solution is to replace all 0 values with FALSE, and all 1s with TRUE.
This might be tricky to do for all different occurences, so I did it separately for all boolean columns. It’s easy to do a replacement in a text editor based on the surrounding content of the literal. For example this was the first error I got, where the 0 value after NULL was invalid:
<p>That should be enough to get you started. Have fun - and let us know what you think :)</p>',NULL,0,0,'draft','en_US',NULL,NULL,1,1429738370592,1,1430050851451,1,1429738370623,1);
^
So I could fix all occurrences of this column by replacing
',NULL,0,(\d),'
with
',NULL,FALSE,$1,'
Then I repeated the replacement from ',NULL,1,(\d),' to ',NULL,TUE,$1,', so we take care of true values as well.
The second error was in the same insert statement, with the boolean value just after the one we fixed. This can be adjusted with a simple replacement, we have to replace
',NULL,(FALSE|TRUE),0,'
with
',NULL,$1,FALSE,'
Then I repeated this one too for true values, by replacing ',NULL,(FALSE|TRUE),1,' with ',NULL,$1,TRUE,'.
Another occurrence was in the tags table, I had to replace ',NULL,NULL,0,NULL,NULL, with ',NULL,NULL,FALSE,NULL,NULL,, and similarly for TRUE.
Fix timestamps
The next group of errors was caused by that in the Sqlite dump script timestamps are represented as bigints (Unix timestamps), which you need to convert to Postgre timestamps.
Converting a Unix timestamp to a Postgre one is simple, you can use the following expression: TO_CHAR(TO_TIMESTAMP(bigint_field / 1000), 'DD/MM/YYYY HH24:MI:SS')
All occurrences can be fixed with a general replacement from
,(\d{13}),
to
,TO_TIMESTAMP($1/1000),
On the other hand, running a general replacement like this is dangerous, because if you have the same content in any of your posts, that will be replaced as well. If you want to avoid that, you should use a couple of more granular replacements that consider the surrounding content of the script.
Difference in the users table
This problem might have occurred to me only because I was using a different version of Ghost: in the INSERT statement for the users table the number of values was one less values than the number of columns, the column tour_text was missing.
So at the end of those lines, I had to replace
NULL,NULL,TO_TIMESTAMP(1456936064255/1000),TO_TIMESTAMP(1429738371778/1000),1,TO_TIMESTAMP(1456936064255/1000),1);
with
NULL,NULL,NULL,TO_TIMESTAMP(1456936064255/1000),TO_TIMESTAMP(1429738371778/1000),1,TO_TIMESTAMP(1456936064255/1000),1);
Missing columns in the clients table
A couple of columns were missing from clients, I looked up their default value in a newly created DB, and based on that I had to replace
INSERT INTO "clients" VALUES(1,'6d74790e-d879-484f-85bb-d1b608e46f52','Ghost Admin','ghost-admin','not_available',TO_TIMESTAMP(1429738370626/1000),1,TO_TIMESTAMP(1429738370626/1000),1);
with
INSERT INTO "clients" VALUES(1,'6d74790e-d879-484f-85bb-d1b608e46f52','Ghost Admin','ghost-admin','','not_available','','enabled','ua','description',TO_TIMESTAMP(1429738370626/1000),1,TO_TIMESTAMP(1429738370626/1000),1);
After all these tweaks, I was able to successfully run the script to load all the data into the DB.
Fix sequences
The last problem was that by purging all the data from the tables and inserting with explicit primary key values we messed up the current values of all our sequences, and insert statements would fail. This can be easily fixed by run the following commands.
SELECT setval('accesstokens_id_seq', (SELECT MAX(id) FROM accesstokens)+1);
SELECT setval('app_fields_id_seq', (SELECT MAX(id) FROM app_fields)+1);
SELECT setval('app_settings_id_seq', (SELECT MAX(id) FROM app_settings)+1);
SELECT setval('apps_id_seq', (SELECT MAX(id) FROM apps)+1);
SELECT setval('client_trusted_domains_id_seq', (SELECT MAX(id) FROM client_trusted_domains)+1);
SELECT setval('clients_id_seq', (SELECT MAX(id) FROM clients)+1);
SELECT setval('permissions_apps_id_seq', (SELECT MAX(id) FROM permissions_apps)+1);
SELECT setval('permissions_id_seq', (SELECT MAX(id) FROM permissions)+1);
SELECT setval('permissions_roles_id_seq', (SELECT MAX(id) FROM permissions_roles)+1);
SELECT setval('permissions_users_id_seq', (SELECT MAX(id) FROM permissions_users)+1);
SELECT setval('posts_id_seq', (SELECT MAX(id) FROM posts)+1);
SELECT setval('posts_tags_id_seq', (SELECT MAX(id) FROM posts_tags)+1);
SELECT setval('refreshtokens_id_seq', (SELECT MAX(id) FROM refreshtokens)+1);
SELECT setval('roles_id_seq', (SELECT MAX(id) FROM roles)+1);
SELECT setval('roles_users_id_seq', (SELECT MAX(id) FROM roles_users)+1);
SELECT setval('settings_id_seq', (SELECT MAX(id) FROM settings)+1);
SELECT setval('tags_id_seq', (SELECT MAX(id) FROM tags)+1);
SELECT setval('users_id_seq', (SELECT MAX(id) FROM users)+1);
After this last fix, your new Ghost blog on PostgreSQL should be up and running!