In the beginning of June I was lucky enough to be able to travel to the NDC conference in Oslo. (Hats off to my employer Travix for providing the budget!)
The NDC has always been one of my favourite conferences besides Build and CppCon (and earlier the PDC and MIX), but so far I have only been following it online by watching the sessions uploaded to Vimeo. This was the first year I had the chance to actually travel to the conference, and it was a splendid experience.
In this post I’d like to tell my impressions, and share the things I learned and found the most interesting.
Venue, organization, etc.
The conference was held at a central location in Oslo, in a big conference building called Spektrum.The large arena in the middle was used to host the booths of the sponsor companies, serve the food, and to provide a casual space for people to hang out between talks. This was also the venue for the two keynote talks during the conference.

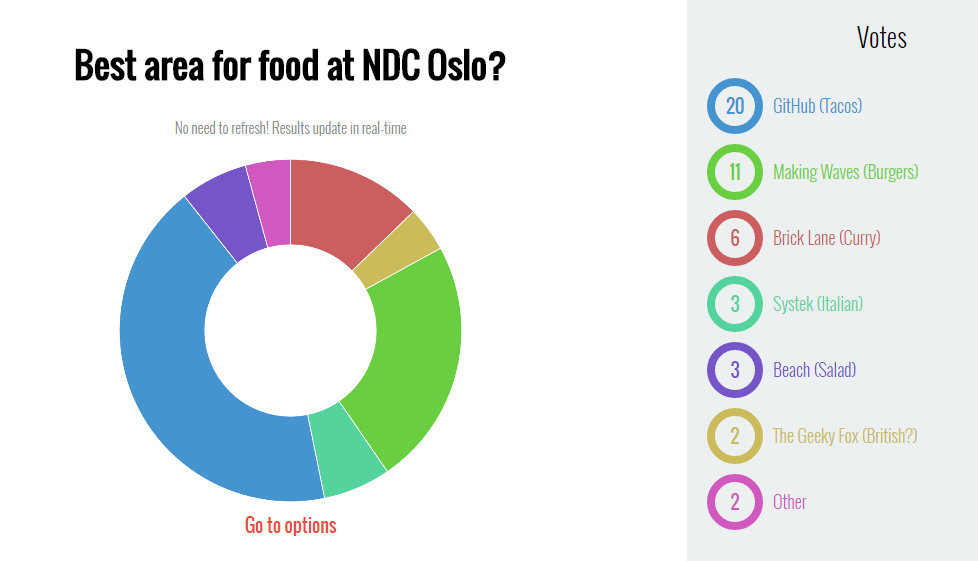
The food also deserves a mention: there was breakfast in the morning, and then lunch was served continuously throughout the whole day. There were several caterers, each serving one or two dishes, which was really cool, because there were many different dishes you could try out, such as sushi, taco, risotto, etc. (And also, the providers were different caterer companies who wanted to show off their product, so I think they all brought their A-game.) Someone even put together a poll to decide which provider was the best, it seems that people enjoyed the GitHub-sponsored tacos the most :)
And what else would help more to concentrate on tech talks all day than some good coffee? Just like the food, coffee was also much better than what is typical at conferences. You could always get a nice espress or a latte with properly steamed milk foam. (I haven’t seen any of those dreaded coffee creamer thingies).
And even some of the baristas were famous tech people :).

I can sum up the work the NDC guys put into organizing the conference with one word: perfect. Every talk started on time, all the tech worked, I didn’t see a single problem with microphones, projectors, etc. The main venue was spacious and well designed, it was never too crowded, even during the busiest periods. The organizers clearly have a lot of experience in putting a conferenc together, they made a great job.
The talks
Although it was pretty good to hang out, eat nice food and drink hipster coffee all day, the most important part of the conference for me was the actual talks. They didn’t disappoint, every talk I went to was high quality. I learned a lot, and I came home from the conference inspired.
In the rest of this post I’d like to share some interesting details I learned at the talks I attended.
Keynote: Yesterday’s Technology is Dead, Today’s is on Life Support (Troy Hunt)
I’m usually not a big fan of keynotes, they tend to be not very informational, and are often very marketingy, especially when they are tied to a particular company.
However, I enjoyed this one a lot. Troy Hunt is a Microsoft MVP, consultant and Pluralsight author, mostly focusing on security. He always delivers amusingly entertaining talks, and he’s also an exceptionally charismatic presenter. This talk wasn’t an exception, it was very interesting and thoroughly entertaining. I recommend giving it a watch if you want a good laugh and would like to learn some interesting trivia about the past, present and future of computing.
ASP.NET Core 1.0 deep dive (Damian Edwards, David Fowler)
I was really looking forward to this talk, since the main technology I use nowadays is .NET Core, so I was really interested in what the PM and the architect on the project will share. The talk was mostly about interesting details from under the hood of .NET, like where the framework is stored on the machine, how to see where the binaries are stored, and even about how someone could create a custom edition of the .NET framework.
There were also some funky demos, like how ASP.NET Core can be run inside of a WinForms application, which - let’s face it - not something you see every day ;).
While the talk was really entertaining, to me it felt a bit random and underprepared. (They even had to troubleshoot on stage when the demos weren’t working at first.)
Despite these complaints it was a good talk, and it’s always nice to see how enthusiastic these guys are about the platform.
ASP.NET Core Kestrel: Adventures in building a fast web server (Damian Edwards, David Fowler)
The second talk by the guys from the ASP.NET team. This was about interesting tricks about optimizing Kestrel, the new cross-platform web server specifically developed for .NET Core.
First they introduced the TechEmpower Benchmarks, which is an independent initiative for comparing the performance of different web frameworks. Although these benchmarks can be somewhat misleading, since low-level, very thin, specialized frameworks can have much higher throughput than all-around, general purpose web frameworks. On the other hand they might be so low-level, that they are not a practical choice for developing complex web applications.
So it might be a bit hard to measure the importance of these measurements, it’s still cool to see how certain frameworks compare to each other. Especially since throughput, response time, and the ability to handle many concurrent requests at the same time is getting more and more important, especially with the advent of technolgies like WebSockets.
Early versions of Kestrel didn’t perform too well on this Benchmark, but since then many things were optimized and in the next round of the TechEmpower benchmarks .NET Core should land at a much better position.
This was a really interesting talks, we’ve seen some tricks and techniques which the average developer definitely doesn’t see in the everyday work, especially when working with high-level web applications.
There are two tricks I found particularly interesting. It seems that at high scale, most of the performance problems in .NET are due to object allocations and garbage collection. So one of the things they always kept in mind during the development of Kestrel was keeping the number of objects allocated as little as possible. (This is something that the Stack Overflow guys have also been blogging a lot about.)
One of the cool optimizations is happening when the beginning of HTTP requests are processed, and the web server is extracting the HTTP verb from the request.
The naive solution would be to read in the first couple of characters into a string, and compare it to the expected methods, such as "GET ", "POST ", etc. They figured out that the longest of these strings we have to take into account is "OPTIONS ", which is exactly eight characters, which, in the case of UTF-8 encoding fits exactly into a single long.
To utilize this fact, Kestrel defines a couple of static readonly long fields, which hold the values of these expected strings, if we interpret their memory representations as a long value.
private readonly static long _httpGetMethodLong = GetAsciiStringAsLong("GET \0\0\0\0");
private readonly static long _httpHeadMethodLong = GetAsciiStringAsLong("HEAD \0\0\0");
...
At the start of processing an HTTP request, the first 8 bytes of the request is read, interpreted as a long, and compared with these predefined values.
long value = begin.PeekLong();
foreach (var x in _knownMethods)
{
if ((value & x.Item1) == x.Item2)
{
knownMethod = x.Item3;
return true;
}
}
return false;
This approach brings two benefits.
- We save on object allocation, since we’re reading in 8 bytes into an existing buffer, and we don’t have to create a
Stringobject. - The other advantage is that comparing two longs is much faster than comparing two strings.
The other thing that stick with me was a really funky trick. I won’t go into the details, but the gist is that in a stream of bytes we want to find the position of the first non-zero byte. The naive solution would be to iterate over the stream one byte at a time and compare them with zero. On the other hand, the CPU works with longs - 8 bytes - anyway, so in a single operation, we are able to compare not one, but 8 bytes. However, this comparison doesn’t give us the position of the non-zero value, but it lets us do the following.
return (i << 3) +
((longValue & 0x00000000ffffffff) > 0
? (longValue & 0x000000000000ffff) > 0
? (longValue & 0x00000000000000ff) > 0 ? 0 : 1
: (longValue & 0x0000000000ff0000) > 0 ? 2 : 3
: (longValue & 0x0000ffff00000000) > 0
? (longValue & 0x000000ff00000000) > 0 ? 4 : 5
: (longValue & 0x00ff000000000000) > 0 ? 6 : 7);
What the above code is doing is basically a binary search in a bit pattern. When we’re comparing our value with 0x00000000ffffffff we get the information whether there is a non-zero value in the left, or in the right side of the 8 bytes. By doing this we can eliminate half of the 8 bytes in a single operation, so in worts case, we will execute 3 comparisons instead of 8.
This stick with me, because I was surprised the simplicity and elegance of this trick. I was always familiar with how binary search worked and how it achieved logarithmic runtime instead of linear, but I don’t know if I could came up with using the same trick not in a sorted collection, but on a bit pattern.
The C++ and CLR Memory Models (Sasha Goldshtein)
I went to this talk expecting to learn about what’s happening in memory when we’re passing objects between the .NET Framework and native Win32 components, for example when using PInvoke or C++/CLI.
Although the talk was really good, its topic was a bit different. It was particularly about the optimizations happening in the compiler and the CPU which can cause our operations to be reordered. It gave clear explanations about the type of bugs this can cause, and what are our options to prevent these, for instance the volatile keyword and the synchronization primitives in the C++ STL.
It was a well-rounded talk with a speaker clearly having confident knowledge about the topic, so definitely give it a look if you’re interested in the above topics.
Functional Programming Lab Hour
This session was unlike the others at the conference. It wasn’t a talk, but rather a freestyle session to which all the Functional Programmer speakers came, the audience could propose some topics which were picked up by the presenters, and then the people attending could chat with the speakers in small groups about anything FP-related.
I learned a lot about the basics of functional programming, and now feel much more confident in jumping in to try F# than I was before. And I think that the concepts we discussed (for instance the importance of immutability, or the problems with nullable variables) can be used to some extent in imperative languages as well. It was interesting that most of the people were coming from a C# background, and almost everybody was interested in F#. (I even felt bad for the Erlang/Haskell/Elixir experts who were nice enough to come and share their knowledge, yet everybody wanted to hear about F# :).)
This session was repeated on all three days, and it worked very nicely. More and more people came on the second and third day, and interesting discussions emerged organically.
This was definitely one of the higlights of the conference for me, I went away from these sessions inspired and motivated. Big kudos to Mathias Brandewinder and Bryan Hunter for organizing!
Fastware (Andrei Alexandrescu)
(On vimeo, this can be found with the title “There’s treasure everywhere”.) I have been following the work of Andrei Alexandrescu for a long time, and have watched many of his conference talks. He’s an energetic, confident and thoroughly entertaining speaker, and is also intimidatingly smart. He used to be a research scientist at Facebook, working on - among other things - optimizing Facebook’s in-house developed just-in-time compiler for PHP. Recently he left Facebook to work full-time on the [D language] he created together with Walter Bright.
The talk was about some new improvements Andrei came up with recently related to the quickselect algorithm found in many standard libraries, and also about some general optimization tricks using sentinels.
The talk was highly entertaining and inspiring, the takeway was never to make assumptions or take things for granted, but always work with an open pair of eyes. To which the improvement of quickselect is a good example, since it’s a rather simple algorithm, yet it hasn’t been this significantly improved in 50 years.
Generic Locking in C++ (Andrei Alexandrescu)
The second talk was about an interesting C++ construct implemented as part of folly, an open source C++ library maintained by Facebook.
The C++11 standard promises that all the const methods of the containers in the standard C++ librar are thread safe, but the non-const functions are not promised to be thread safe, so we should call them from only a single thread at a time.
In the STL the type std::shared_mutex provides us a way to use a reader-writer lock, with which we can allow multiple readers into a critical section, but only a single writer (without any readers).
The way how the reader-writer lock works has a nice simmetry with the promise of the C++ standard, so we can use a lock to control concurrent access to the containers in the STL.
std::shared_mutex mutex;
std::vector<int> vect;
...
{
// Reading, need a shared lock
std::shared_lock<std::shared_mutex> lock(mutex);
int length = vect.size();
}
{
// Modifying, need an exclusive lock
std::unique_lock<std::shared_mutex> lock(mutex);
vect.clear();
}
The type introduced in folly is called Synchronized. It is a class template, which we can use to wrap other classes in it, and it makes all the methods of the underlying class available on the wrapper. Upon calling functions on Synchronized, it uses the proper synchronization mechanism before forwarding the call to the wrapped object. Thus we can safely call the methods on Synchronized concurrently without worrying about manually doing any locking.
Synchronized<std::vector<int>> syncVect;
...
// Calling a const method, uses shared lock automatically
int length = syncVect->size();
// Calling a non-const method, uses exclusive lock automatically
syncVect->clear();
Note that the functions size() and clear() are not defined on the type Synchronized, yet, we can call those on the syncVect object. This is made possible by the code-generation capabilities of C++ through template metaprogramming.
To me this was fascinating, especially since I mostly use C# in my everyday work, with which - as far as I know - something like this is impossible.
Sometimes we tend to think that C++ is an old and outdated language, which is only used today for low-level things like OS-development or device drivers. The takeaway from this talk for me is the fact that C++ is still alive; very exciting and interesting things are happening in its community, and really smart people are working on improving it continuously.
These two talks by Andrei were one of the highlights of NDC to me. If you only watch one thing from NDC, I definitley recommend these.
C# Today and Tomorrow (Mads Torgersen)
This was the standard talk that Mads - the lead designer of C# - gives at almost all big conferences, and it’s always updated with the new features coming to the C# language.
Since I’m mostly working with C#, I was looking forwad to this session, and it lived up to my expectations. It was the right combination of entertaining, interesting and informational. Also, the new features coming to C# seem like really nice additions.
What was interesting to me is that most of the upcoming features seem to be borrowed from functional languages, or related to functional programming and immutability.
One of the bigger new features is pattern matching, which makes the switch statement much more powerful, by removing the limitation that we can only have compile-time constants in the case clauses, but we will be able to use dynamic conditions, and we can also use a new thing introduced called patterns.
Geometry g = new Square(5);
switch (g)
{
case Triangle(int Width, int Height, int Base):
WriteLine($"{Width} {Height} {Base}");
break;
case Rectangle(int Width, int Height):
WriteLine($"{Width} {Height}");
break;
case Square(int Width):
WriteLine($"{Width}");
break;
default:
WriteLine("<other>");
break;
}
The other significant addition to the language will be tuple types, which will make it easier to work with methods that have to return multiple values. In the current version of C#, if we need to return multiple values from a method, we have a couple of options, of which none of is too good.
We can use out parameters.
public void Tally(IEnumerable<int> values, out int sum, out int count) { ... }
We generally don’t like this, since it’s syntactically weird, especially if we want to use the result of the method inside an if condition.
We can use the Tuple type.
public Tuple<int, int> Tally(IEnumerable<int> values) { ... }
This is not ideal either, since the type Tuple<int, int> makes the signature of the method hard to understand, and at the call site we will always forget which one is Item1 and Item2.
And we can explicitly define a return type.
public struct TallyResult { public int Sum; public int Count; }
public TallyResult Tally(IEnumerable<int> values) { ... }
This is an ideal solution when we are calling the method, but these helper types are boilerplate cluttering up our codebase.
C# 7 will make it possible to return multiple values from a method, which can be than accessed outside on a single variable, as if the variable had a type containing those properties.
public (int sum, int count) Tally(IEnumerable<int> values) { ... }
var t = Tally(myValues);
Console.WriteLine($"Sum: {t.sum}, count: {t.count}");
(Basically this is a syntactical sugar, which generates a type during compilation. And of course, this is not a novel idea, Golang and Swift - to name two examplex - have this too.)
A technical detail: the object t is going to be a value type.
The best thing about this talk was that Mads hung around at the Microsoft booth after the talk for more than an hour and had a chat with the “fans” :). He was really nice and approachable, and it was interesting to hear his personal opinions.
We asked him about the possible introduction of tail recursion to C#, he confirmed that it’s not on the roadmap, so probably won’t be introduced in the coming years (although there is no technical reason preventing it). We also discussed having a notion of purity, in terms of identifying methods which are mutating state and which don’t, similarly to const methods in C++. This is not on the roadmap either. Actually, this was part of a research project at Microsoft called Midori, which was discontinued, and this purity concept had consequences which caused more problems than what it solved.
On the other hand, the thing which they are actually thinking about is providing a way to do compile-time code generation. The example he gave is the implementation of the INotifyPropertyChanged interface.
When implementing an MVVM application with WPF, Windows Phone or WinRT, in order to implement data binding, you have to implement all your view model properties the following way.
private string customerName;
public string CustomerName
{
get
{
return this.customerName;
}
set
{
if (value != this.customerName)
{
this.customerName = value;
NotifyPropertyChanged();
}
}
}
This is quite a lot of boilerplate code, and this is what they would like to make generatable. The actual syntax to do it is not fleshed out yet, but one of the concepts is to be able to define a simple auto-generated property, and put an attribute on top of it to say that custom code should be generated for it.
[GenerateNotifyPropertyChangedProperty]
public string CustomerName { get; set; }
(This code example is made up by me based on what Mads told us.) And there would be a way to specify the template which generates the actual code, and then either through a manual action, or upon saving the file, the code based on the template would be generated.
This feature sounds very exciting to me, but probably we are quite far from actually seeing it becoming a part of C#, since it’s very early in the design process.
Conclusion
This was the first time I went to NDC, and it was a great experience. I learned a lot, I came home inspired and motivated, and the overall vibe of the conference was tremendously good. All the sessions are going to be uploaded to Vimeo (most of them are already up), I recommend everyone to check them out. I hope I will have the opportunity to go back next year, I will definitely try to do so.