Introduction
When using Couchbase, sometimes we want to update the expiry of all of the documents stored in a bucket. In my case it was in a project where initially we weren’t sure how we want to handle document expiry (either periodically run some query on our data store, and backup and remove all the old elements—or use the expiry mechanism built into Couchbase), so we ended up deciding we’ll just insert all our documents without expiry for now, and we’ll figure out later how we want to handle the problem. And granted, before we knew it, we had 17 millions documents without expiry in our bucket. Oops.
At that point we decided we want to use Couchbase’s built-in expiry mechanism, so we’ll set the Expiry property on every new document we store.
And we realized that we also retroactively have to set the expiry of all our existing documents too. This turned out to be not exactly trivial. In this post I’ll describe how I ended up doing it.
(I was using the .NET SDK, so that’s what you’ll see in the code samples, but the approach described here can be used with any of the other SDKs, or even with the CLI.)
The approach
I started googling to see how we can update the expiry for all documents in a bucket, and quickly found out that Couchbase has no built-in operation for updating the expiry in bulk. Based on my investigation the best option was to simply query over all the document ids in our bucket, and update the expiry of them one by one.
Query all the keys in a bucket
In order to be able to iterate over all our documents, we have to be able to query the keys in a bucket, but that’s not completely trivial either. Unlike SQL, we can’t just iterate over all the elements by default, we have to utilize an index or a view to do that. One way to achieve this is to create a simple view, which retrieves the ids of our documents.
Create the view
Creating the necessary view is really simple, we can do it from the Couchbase management console. On the “Data Buckets” screen click on the Views button next to our bucket.
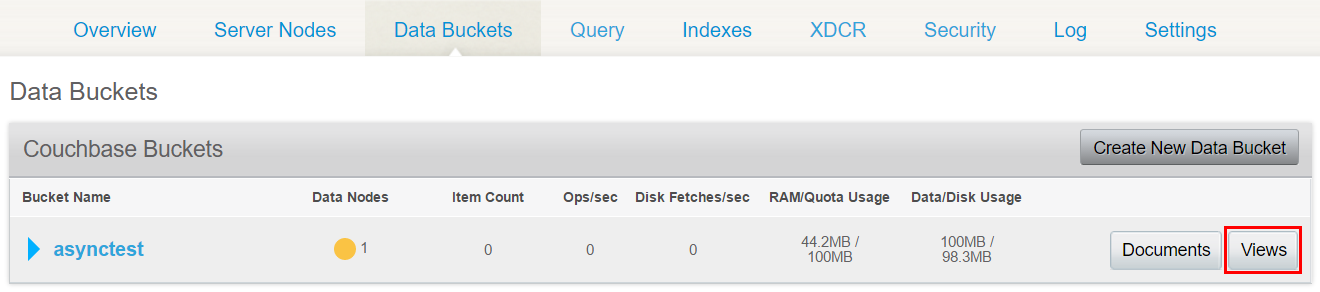
Then click on “Create Development View”, and give it a name. I used the name “all_keys”.
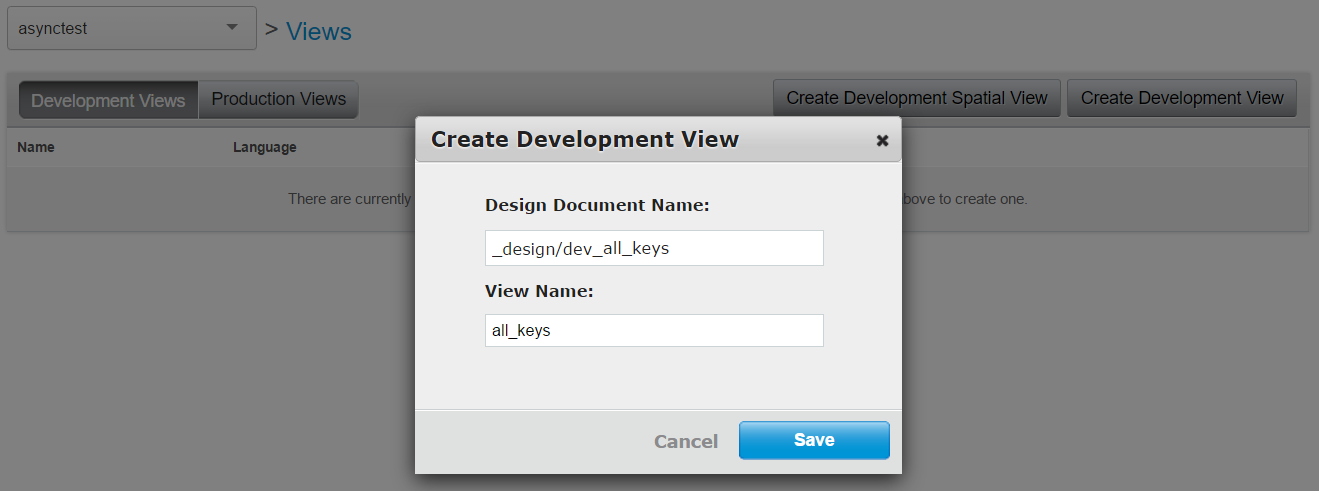
On the View screen we can customize our query. Actually, the query generated by default is suitable for us, because it already returns our document keys.
The only thing I changed in the query was that I removed even emitting the meta.id, because the keys are already return by the view without this, so removing this will make our downloaded view file slightly smaller. This is the view I used.
function (doc, meta) {
emit(null, null);
}
We can test our view by clicking on the “Show Results” button. After this, go back to the “Views” page and click on the “Publish” button.
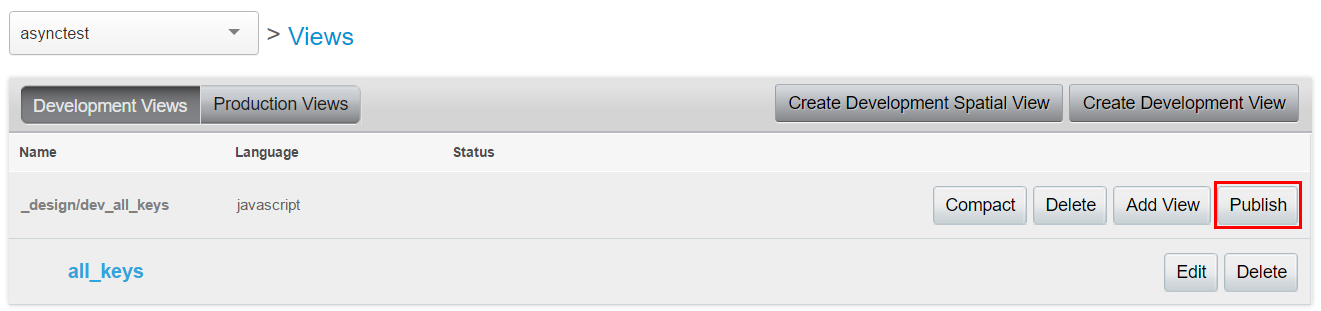
By doing this we “promote” the view to production, and it’s gonna query our whole bucket instead of just a small portion for development. Then we can switch to the “Production” tab and open our published view and test it.
Querying the view
The simplest way to query a view is to call the HTTP endpoint Couchbase is providing for our view. If we go to the page of the View, we can find an example of this URL at the bottom of the page.

Gotcha: make sure to get the url from the production view, and not the development one, since the latter will only contain a portion of our data.
This is an example of the query url:
http://mycouchbaseserver:8092/mybucket/_design/all_keys/_view/all_keys?connection_timeout=60000&inclusive_end=true&limit=6&skip=0&stale=false
Where the limit and skip arguments specify the portion of the view we want to retrieve.
(Querying the view through the SDK: We can also query the view with the SDK, for example in C# we can use the bucket.CreateQuery() method, but to simply get all the keys I think it’s easier to just simply use the HTTP endpoint.)
Processing the data: a failed attempt
At first it seemed to be a reasonable approach to simply query the view in batches (let’s say 1000 documents at a time), and then update the expiry for each of them with the SDK (for example in the .NET SDK we can update the expiry with the Touch() method).
This is a pseudo-code implementation of this approach:
var baseUrl = "http://mycouchbaseserver:8092/mybucket/_design/all_keys/_view/all_keys?connection_timeout=60000&stale=false&inclusive_end=true";
var batchSize = 100;
var cnt = 0;
var expiry = TimeSpan.FromDays(10);
while(true)
{
var documents = DownloadDocuments(baseUrl + $"&limit={batchSize}&skip={cnt*batchSize}");
foreach (var doc in documents)
{
bucket.Touch(doc, expiry);
}
if (documents.Count < batchSize)
{
break;
}
cnt++;
}
The code seems to make sense, and it works too. The problem is its performance. It turns out that for some reason, executing the query takes more and more time as the number of skipped document increases (as we get further and further through our documents).
In my case, with 17 million elements the response time of the query was the following:
- Querying 1000 elements at the beginning (
&skip=0&limit=1000): under 200ms - Querying 1000 elements starting from 500,000 (
&skip=500000&limit=1000): 5 seconds - Querying 1000 elements starting from 10,000,000 (
&skip=10000000&limit=1000): 2 and a half minutes
So this approach was not working, as my script was progressing through the bucket, it got slower and slower, after a couple of hundred thoursand documents it was barely doing any progress.
I investigated quite a lot about the cause of this. I suspect it’s caused by not having some necessary index to be able to efficiently query any portion of my view (I also asked the question here). Yet, however I tried to set up primary or secondary indices, I couldn’t speed the query up.
Then I had a different idea.
Brute force!
I had 17 million documents in the bucket, which sounds a lot, but actually my view is only returning the keys and nothing else, the output looks like this (depending on your keys of course, which are GUIDs in my case):
{"id":"000001ba-c4c9-4691-9c48-ca4b0cb1fe80","key":null,"value":null},
{"id":"0000023c-f18a-4cd2-94c2-5ad9533b7c82","key":null,"value":null},
{"id":"00000275-0fd7-4aff-bd5c-626ddd087331","key":null,"value":null},
How large the whole Json can be? Well, one line is 70 characters (70 bytes in UTF8), so it shouldn’t be much more than 17,000,000 * 70 = 1,190,000,000 bytes, which is ~1,134 MB. That doesn’t sound too bad. Can we maybe simply download the whole view in one single go, save the Json as a file, and do the whole processing based on that file? Can Couchbase return all the 17 million documents in one go? It turns out that this works without any problem, Couchbase can return the Json for the whole view without breaking a sweat.
I simply used curl to download the json with the following command.
curl -o allkeys.json http://mycouchbaseserver:8092/mybucket/_design/all_keys/_view/all_keys?inclusive_end=true&stale=ok&connection_timeout=6000000
A couple of things to note about the URL:
- I removed the
limitandskiparguments. This is the important part, this’ll make the query return all the elements. - I increased the
connection_timeout. (Didn’t really calculate it, just added 3-4 zeros at the end.) - Changed the value of the
staleargument took. In theory this makes our query faster (I didn’t measure), since it enables Couchbase to return stale data (which is fine in our case, since we’re interested only in the keys, which shouldn’t change anyway.)
Downloading the whole view took a couple of minutes, and it resulted in a ~1.2 GB json file. So far so good!
Update the expiries
Iterating over the lines in this json file shouldn’t be difficult with our favourite technology, we can use any of the SDKs out there (or probably we can even do it in a bash script with the CLI).
I used the .NET SDK to implement this, with the following little console application.
using Couchbase;
using Couchbase.Configuration.Client;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Net;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
namespace ExpiryUpdater
{
class Program
{
private const string serverAddress = "http://mycouchbaseserver:8091/pools";
private const string bucketName = "mybucket";
private const int batchSize = 1000;
private const int chunkSize = 10;
// Regex pattern assuming that the lines in the json file are in the format
// {"id":"0000023c-f18a-4cd2-94c2-5ad9533b7c82","key":null,"value":null},
private const string idPattern = ".*\"id\":\"([^\"]*)\".*";
private static readonly Regex idRegex = new Regex(idPattern, RegexOptions.IgnoreCase | RegexOptions.Compiled);
private static readonly TimeSpan expiry = TimeSpan.FromDays(90);
static void Main(string[] args)
{
var allLines = File.ReadAllLines(@"C:\Temp\allids.json");
allLines = allLines.Skip(1).Take(allLines.Length - 3).ToArray();
Console.WriteLine("Starting updating expiry. Batch size: {0}", batchSize);
var config = new ClientConfiguration()
{
Servers = new List<Uri>
{
new Uri(serverAddress)
}
};
// Make sure the SDK can handle multiple parallel connections.
ServicePointManager.DefaultConnectionLimit = chunkSize;
config.BucketConfigs.First().Value.PoolConfiguration.MaxSize = chunkSize;
config.BucketConfigs.First().Value.PoolConfiguration.MinSize = chunkSize;
ClusterHelper.Initialize(config);
var bucket = ClusterHelper.GetBucket(bucketName);
int cnt = 0;
int processed = 0;
var sw = Stopwatch.StartNew();
while (true)
{
Console.Write("Batch #{0}. Elapsed: {1}. ", cnt, sw.Elapsed);
var batchLines = allLines.Skip(cnt * batchSize).Take(batchSize);
Console.WriteLine(
"Items: {0}/{1} {2}% Speed: {3} docs/sec",
cnt * batchSize,
allLines.Length,
(int)Math.Round((100 * cnt * batchSize) / (double)allLines.Length),
processed / sw.Elapsed.TotalSeconds);
Parallel.ForEach(batchLines, new ParallelOptions { MaxDegreeOfParallelism = chunkSize }, line =>
{
var id = idRegex.Match(line).Groups[1].Captures[0].Value;
var result = bucket.Touch(id, expiry);
processed++;
if (!result.Success)
{
throw new Exception($"Touch operation failed. Message: {result.Message}", result.Exception);
}
});
if (batchLines.Count() < batchSize)
{
break;
}
cnt++;
}
sw.Stop();
Console.WriteLine("Processing documents done! Total elapsed: {0}", sw.Elapsed);
Console.ReadKey();
}
}
}
Some notes about this code.
- Since it’s throwaway code, there is not much error handling. If opening the file or the regex processing fails, it’ll just crash with an unhandled exception. But it was fine for my purposes.
Parallel.ForEachis not an ideal approach for this scenario, since this work is not CPU-bound, but IO-bound.
What I would’ve rather done is to stay on one thread, start a bunch of asynchronous touch operations withTouchAsync, and then wait for all the tasks to finish in parallel withTask.WaitAll(). However, for some reason this approach didn’t work for me,TouchAsync()throws an exception, and I couldn’t figure out why, so I just stick withParallel.ForEach(again, throwaway code).- I think reading in the giant json file is not the most performant, when we’re doing
SkipandTake, and thenToArray, we are probably doing a copy, but I didn’t want to spend more time to optimize. - There is no science behind the batch size and chunk size values, I tried a couple of different ones, and these seemed to be the best.
The performance of this script will probably vary a lot depending on your network speed, the distance between you and your Couchbase server, the number of nodes in the cluster, and their performance, etc. In my case the script was processing ~500 documents per second, so running it for 17,000,000 million items took approximately 10 hours.
By running this application, we can watch the progress in the terminal window.
If it crashes in the middle for any reason (for example we are disconnected from the network), or you have to turn off your machine, don’t worry. Simply take a note of what was the last batch you processed, then change the cnt variable to that value, and start it again.
One thing to keep in mind is that this approach only updates the documents which are in the bucket at the time of downloading the json of the view, so this is ideal to use when we’ve already updated our application code to take care of the expiry of new documents.
I hope this post can save some time for people struggling with the same issue. And if you manage to figure out a more sophisticated approach to do this, all suggestions are welcome in the comments.