Introduction
In the last post I described the quirks and problems I encountered during getting started with using Couchbase Server in a production environment.
When we are storing complex objects, by default the .NET Couchbase SDK uses Json.NET serialization. It is possible to create indices and views on this Json structure, and execute custom queries to filter our documents based on their Json property values. I guess in this scenario we can think of Couchbase as a NoSQL Document-store.
On the other hand, there is another scenario for using Couchbase, and that is to utilize it as a simple key-value store. In this scenario we don’t care about the internal structure of the documents, because we don’t want to use any custom indices or queries, we only want to query for single elements based on their keys.
When we use a database or a document store, we would like to achieve the following things (amongst others).
- Use as little disk space as possible.
- Use as little memory as possible.
- Store and return objects as fast as possible.
With my colleagues we figured that if we let the SDK use its default Json.NET serialization, we are definitely not operating optimally regarding the first two goals. Json serialization is much less verbose than - let’s say - XML, but still, a Json document can usually be heavily compressed compared to its raw Json representation. And because we only use Couchbase as a key-value store, having the structure of a documents as raw Json is completely wasted.
An obvious approach to improve this situation would be to store our documents compressed in Couchbase. Before starting to implement something, I wanted to ask around to see if there is a built-in solution to achieve this, so I posted a question in the official Couchbase developer forums.
I received the suggestion that the simplest way to do this would be to simply compress my documents into a binary blob before inserting them into the Couchbase server.
The easiest way to do this would probably to store the content as a compressed byte array. A byte array will by-pass the serialization process and be stored on the server as a binary blob.
However, someone else warned me about the fact that Couchbase already uses some kind of compression when it stores documents on disk, so by manually compressing objects I would just put extra load on the client without achieving any improvement.
On another note, I’m not sure compressing the documents before serializing to Couchbase is necessary. Couchbase already compresses the data store when it’s persisted to disk on the server.
So you could just serialize as JSON, and let the server pick up the processing load of compression/decompression.
So I decided to do a simple benchmark to figure out how much we can gain from using compression, and how significant its drawbacks are.
Implementing compression
My implementation of compression is based on the JilSerializer described by Jeff Morris in his blog post about improving the performance of the built-in serializer. I extended his code with using the GZipStream class included in the .NET Framework. You can find the full code for this serializer in this gist.
(I also replaced the Jil serializer with Json.NET, because I got a weirdly long startup time with the Jil serializer, for which I couldn’t figure out the reason yet.)
This implementation seemed to work nicely, now it’s time to measure whether it brings any value to the table.
Benchmark
I have learned many times that it’s frighteningly easy to get benchmarks wrong. Very often we get misleading results, because we overlook something: the system under test is not warmed up, the measured timing is affected by some mechanism we don’t want to test, or simply the results end up being too random.
In my experience the best tool to avoid these problems is to make our benchmark as simple as possible.
The simplest approach I could come up with is the following.
- We take a rather large C# object, ~400 Kbytes if serialized into Json.
- Insert this document into Couchbase, and then retrieve the same document.
- Repeat this a thousand times.
- During this process, measure the total elapsed time and also the average time needed for the insert and the retrieval.
- After running the benchmark, examine the memory and the disk usage of the Couchbase bucket.
I’ve run this benchmark with both the default serializer and the simple GZip serializer described above. The timings are measured by the benchmark code, but I couldn’t find any way to get the memory and disk usage out of the server programatically with the Couchbase SDK, so I read those from the management interface:
Test results
I did the first set of tests with a semi-random data set. I generated some random Json objects using JSON GENERATOR, and generated a C# object model with json2csharp. You can find the data and the code in this Github repository.
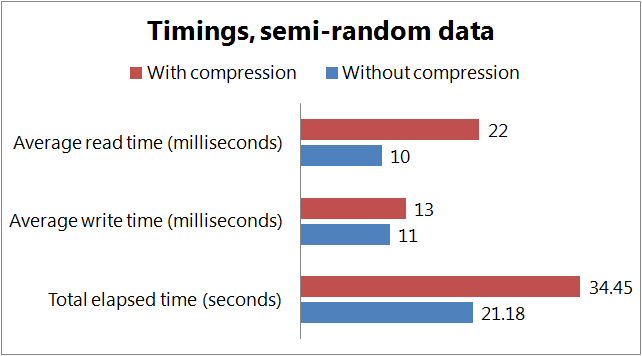
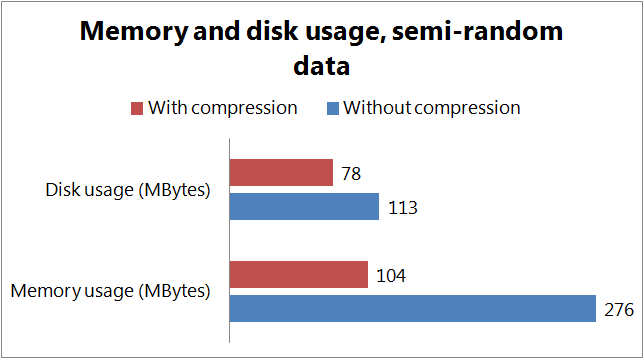
The results for the 1000 inserts and retrievals are the following
I did the second set of tests with a real-life dataset I extracted from our production cache. With this data I got the following results
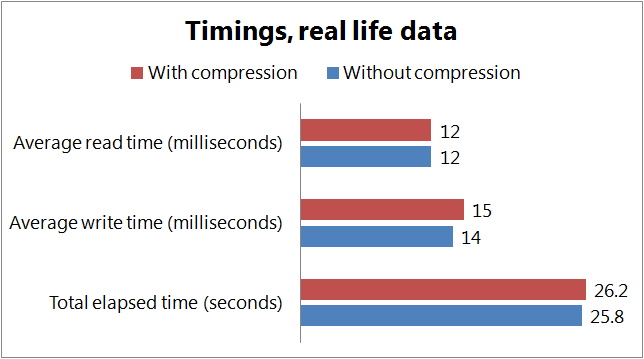
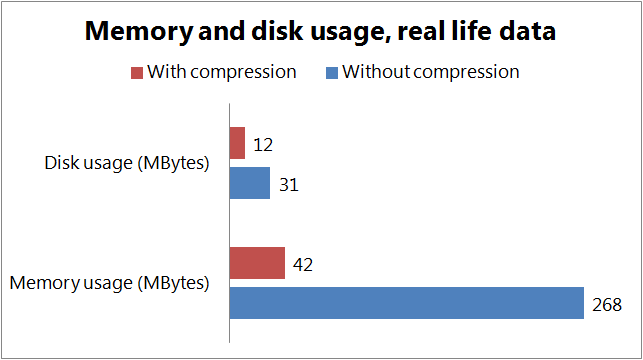
The results suggest that
- Inserting and reading are slower if we use compression on the client side. Reading compressed data can be significantly slower if we have to decompress, the writing seems to be less affected. The penalty we have to pay for compression seems to depend a lot on our data set, the difference might be negligible.
- This penalty is contrasted by the gain we can see in the memory and disk usage. Both the disk and memory usage is significantly lower if we use compression. The saving in memory usage was 63% for the random data, and 85% in case of the real data. The disk usage was 31% lower when storing random data, and 62% lower in case of real data.
We can clearly see that the nature of our data set greatly affects the extra time needed for the compression and the amount of savings we can achieve in the memory and disk usage. Data sets containing pseudo-random data, like statistical information with lots of numbers can be compressed less effectively than datasets containing lots of text.
Conclusion
In the scenario I’m working with, using compression is clearly worth it: the extra computation time needs to be payed is negligible, however, the saving in memory consumption and disk usage is significant.
However: if you want to make a decision for your scenario, I definitely advise you to do some measurements with your own dataset. To give a starting point for doing your own benchmark, I uploaded the code I used to this Github repository.
(In the code I’m using the Couchbase server running on localhost, and the benchmark uses two buckets, withcompression and withoutcompression. Flushing needs to be enabled for the buckets, because the benchmark completely clears all the documents when it starts.)