Posts in this series:
- Part 1: Hash tables
- Part 2: .NET implementation
- Part 3: Built-in GetHashCode
- Part 4: Custom GetHashCode
General guidelines
This is the last part in the series about the Dictionary class and the GetHashCode method. In this post we’ll take a look at what to look out for when implementing a custom GetHashCode method. In the previous post we’ve seen how the built-in GetHashCode works.
We create a custom implementation when we want to deviate from the default behavior, namely:
- In case of a reference type, we don’t want to base the hash code on the reference of the object, but rather on its value (by default, the hash code is calculated based on the reference).
- In case of a value type, we want to base the hash code on only a subset of its fields (by default, the hash code depends on all of the fields).
This post won’t be about what algorithm to use when calculating the actual hash value. That’s a much deeper topic, and it’s not particularly my area of expertise. If you’re interested in a guide for that, check out chapter 3.9 of Effective Java, that is a good starting point.
However, here are some general rules of thumb to follow (source: Object.GetHashCode documentation on MSDN).
- Equality of hash keys does not imply the equality of the objects itself. This is logical, because there are much more possible different objects than different hash codes.
- However, if two objects are equal (so that obj.Equals(other) returns true), their hash codes should be equal too.
- If a class overrides GetHashCode, it should do so with Equals too, and it should work in the way defined in the above two points.
- During a single execution of an application, GetHashCode should consistently return the same value for an object every time, if there was no modification in the state of the object. What this means in practice is that we shouldn’t make the implementation depend on random values, or the current date or time, etc.
- GetHashCode should not throw an exception.
- The implementation should be generally inexpensive to execute. Otherwise, it might slow down all the classes depending on it, for instance the HashTable and the Dictionary.
In practice this means that we shouldn’t do anything crazy in it, we shouldn’t start a background thread, do a DB-query or an HTTP-call. Also, the implementation should be fairly simple in order to execute fast.
Note: Sometimes it makes sense to make a hash function complicated, so it’s guaranteed that it takes a long time to compute, so that an attacker cannot mass-compute the hashes of many values. Such a function is called a cryptographic hash function, but that shouldn’t be implemented with Object.GetHashCode. If you’re interested, look up the HashAlgorithm class.
These are all requirements on which classes using hash codes can depend on. So if you want to use GetHashCode in your own code, then for example you don’t have to handle exceptions, or worry about calling it many times slowing your application down, because every well-behaving .NET class should have a GetHashCode implementation which is fast, and does not throw.
Mutability
Even if we adhere to the above points, we can have a different set of problems when mutability comes into the picture.
The root cause of the problem is the same as what we looked at in the previous post when discussing the built-in GetHash-code implementation of value types: we get the hash code by calling GetHashCode, the implementation of which depends on some mutable field of the object.
Then we process that object depending on the code, for instance we put it into a bucket of a hash map.
If we mutate the object so that its GetHashCode method returns a different value, then the state of our program becomes inconsistent. That’s what we saw in the previous post, when we weren’t able to find our entry in the Dictionary any more.
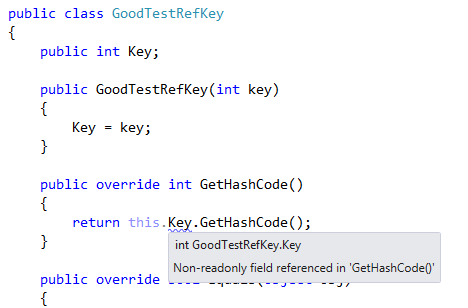
An easy solution to this problem is to follow the general rule, that no mutable fields should be used in the implementation of GetHashCode. As we’ve seen in the previous post, ReSharper warns you about this:
The importance of Equals
As noted above, if we override GetHashCode, we must do so with Equals, in a way that they are “consistent”, so that if two objects are equal, then they also have the same hash code.
The classes using GetHashCode depend on this requirement, so if we don’t adhere to it, then we quickly get into an inconsistent state.
The following example shows a class which has an incorrect implementation.
var testDict = new Dictionary<WrongClass, string>();
var key = new WrongClass("key1");
testDict.Add(key, "content");
var contains1 = testDict.ContainsKey(key); // Returns true
var contains2 = testDict.ContainsKey(new WrongClass("key1")); // Returns false
var entry1 = testDict[key]; // Returns the entry
var entry2 = testDict[new WrongClass("key1")]; // Throws KeyNotFoundException
Conclusion
With this I finish this series of posts about the Dictionary. When using built-in classes of the framework, it’s always nice to have at least some understanding of what is going on under the hood. Maybe in the future I’ll take a look at another class of the .NET Framework.
And if you’re uncertain, you can always take a look at the source code at the Reference Source.